Logstash
-
데이터 수집 및 처리를 위한파이프라인을 갖는Data Flow처리기 -
Input~Filter~Output으로 이뤄지는 프로세스 처리 -
각 단계에서는 다양한
Plugin이 적용 가능하다. -
하나의 Logstash Instance에 여러 pipeline 구축 가능 (
Multi Pipelines) -
Multiple Input, Multiple Output가능 -
Persistant Queue로 설정 가능 -
기본적으로는
in-memory queue로 설정되어 활용되기 때문에 장애에 취약한 부분이 있음 -
Persistant Queue로 활용함으로써 Input Data가Disk에 저장되고 프로세서 처리 및 출력이 완료되고 난 뒤Persistant Queue에 통지하는 방식이 가능 -
만일 중간에 서버가 Shutdown 되는 등의 상황이 발생하게 되면 logstash 재시작 시
Disk에서 아직 통지되지 않은 데이터를 재활용 가능(데이터 유실 X)
LogStash 설치
설치 환경은 Ubuntu 16.04 LTS 이다.
Logstash는 여타 오픈소스처럼 쉽게 설치 가능하다. 공식 홈페이지에서 직접 다운로드 받거나 wget 명령어로 CLI 환경에서 다운로드 가능하다.
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.11.1-linux-x86_64.tar.gz
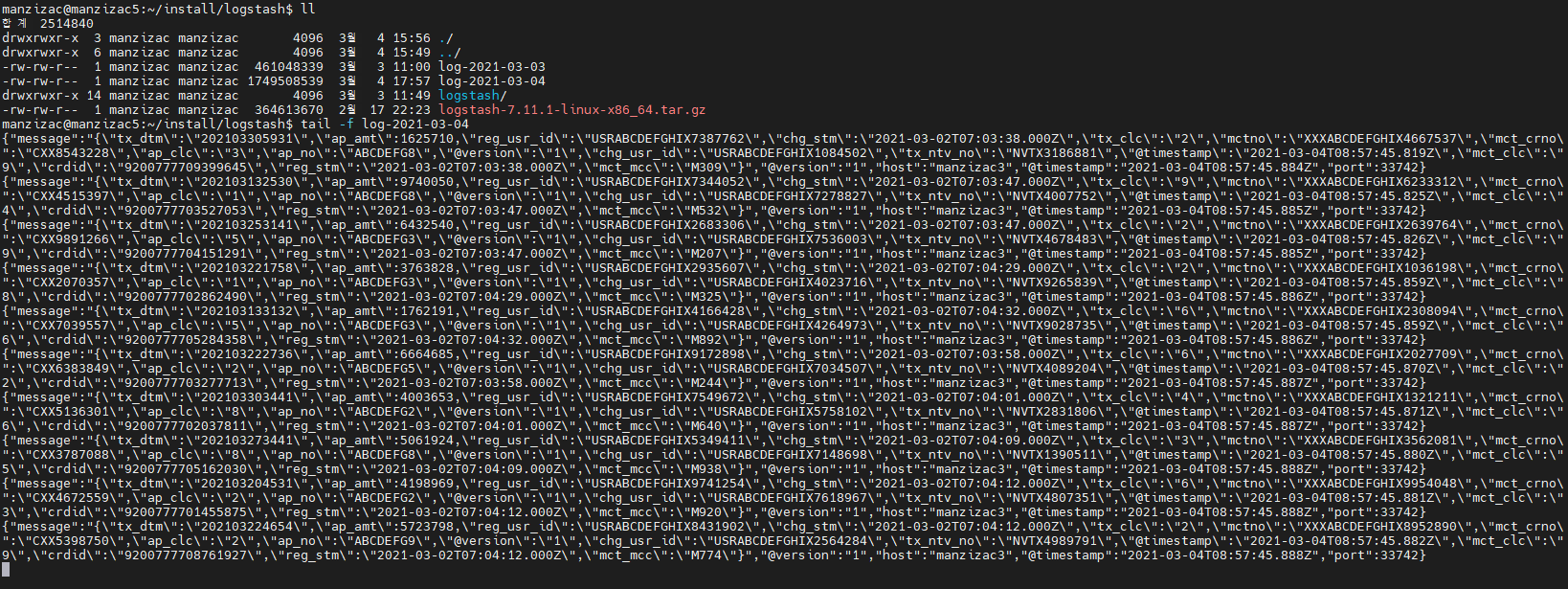
다운로드 한 뒤 압축을 해제한 logstash 패키지의 파일 구성은 아래와 같다.
Logstash 설정 파일들
Logstash는 실행하는데 필요한 설정 파일들이 존재하는데, 두 가지 타입 이 존재한다.
- Settings Files(시작과 실행에 대한 옵션을 정의)
- 두 개의 파일로써,
logstash.yml과pipelines.yml. - logstash/config 디렉토리에 위치한다.
- 두 개의 파일로써,
- Pipeline Configuration Files(파이프라인 처리에 대해 정의)
- 사용자 정의 파일로써
사용자가 직접 생성해야 한다. 일반적으로xxx.conf와 같은 이름을 갖는다. - logstash/config 디렉토리에 샘플 파일이 존재(
logstash-sample.conf)
- 사용자 정의 파일로써
1. Settings Files
- config/logstash.yml
logstash의 실행 제어를 위한옵션 설정 파일이다.- pipeline 설정, configuration file 위치, 로깅 옵션 등과 같이 다양한 기본 설정이 가능하다.
logstash실행 시 별도의 옵션을 주는 것과 같이 해당 파일에 기술하면 적용된다.- logstash.yml 옵션 목록
- config/pipelines.yml
- 기본적으로
One instance, Multiple pipelines를 위해 사용하는 설정 파일이다. - 파이프라인의 개수, 각 파이프라인의 ID, 각 파이프 라인의 conf 파일 등을 설정한다.
- 명시적으로 설정되지 않은 설정 값들은
logstash.yml파일에 지정된 기본 값으로 재설정된다. logstash를 시작할 때 아무런 옵션 인자 없이 실행하면 자동으로pipelines.yml파일을 읽는다. 만일 읽지 않게끔 하려면-f,-e와 같은 옵션을 주어 실행한다.- pipelines.yml 옵션 목록
- 기본적으로
2. Pipeline Configuration Files

.conf파일로써 유저가 직접 생성한다. 파이프라인 프로세스 처리, 즉Input~Filter~Output에 대하여 기술한 파일이다.- 각 단계에서 사용할 플러그인을 적용할 수 있다.
JDBC 플러그인과 TCP 플러그인을 활용한 대용량 데이터 공유/전송 구성
지금까지 간단하게 logstash의 구성을 알아봤다. 이번 장에서는 logstash 설정 파일들을 직접 수정하고 플러그인을 적용함으로써 대용량 데이터 공유/전송 구성 방법에 대해 알아보겠다.
전체적인 개요도는 아래와 같다.
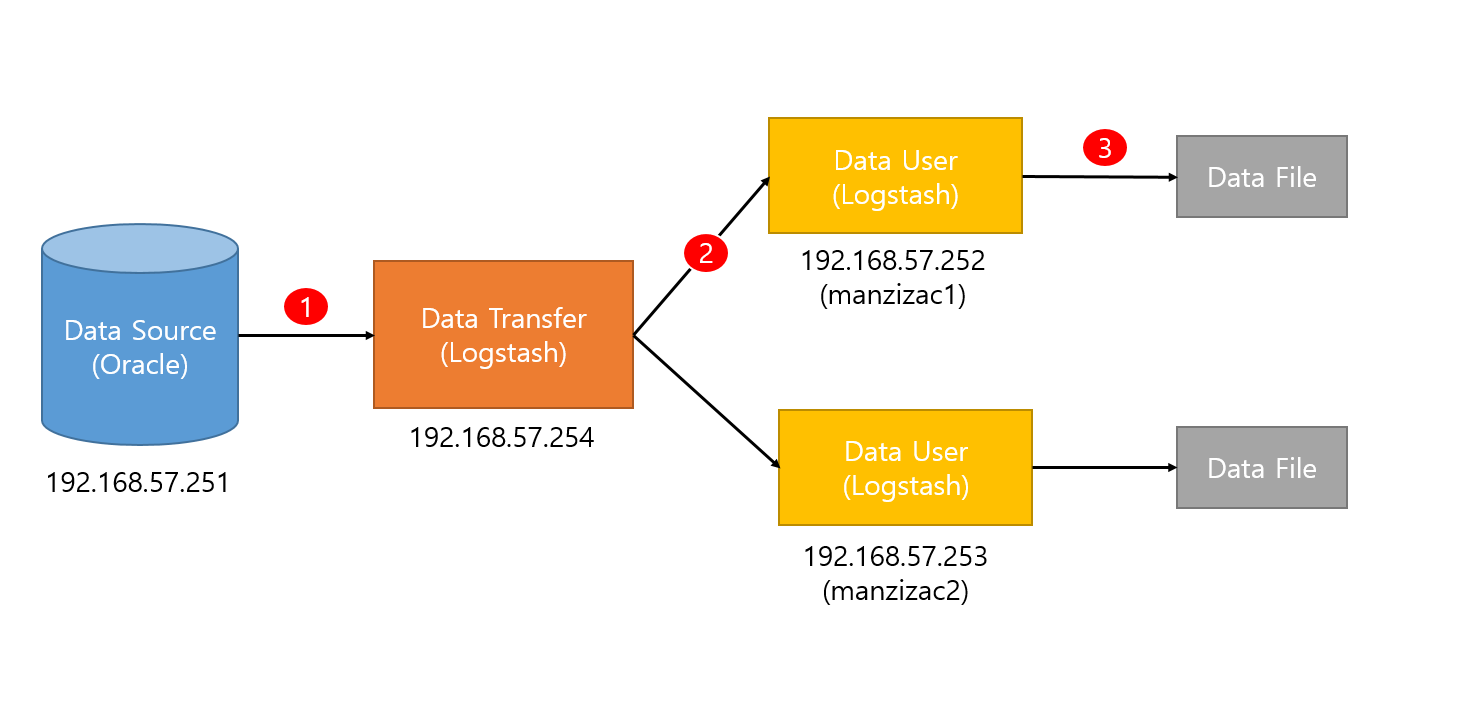
(1) 오라클 데이터베이스로부터 Data Transfer가 데이터를 읽어와서
(2) Data User들에게 전달하고
(3) Data User들은 이 데이터를 로컬에 Data File로 저장한다.
각 순번에 해당하는 내용을 하나씩 살펴보도록 하겠다.
(1) Data Transfer 설정
JDBC 플러그인을 활용한 데이터 입력 구성과 TCP 플러그인을 활용한 데이터 출력 구성
개요도에서 (1)번과 같이 DB로부터 데이터를 읽어들이기 위해서는 Data Transfer의 input 단계에서 JDBC 플러그인을 사용해야 한다. 또한 (2)번과 같이 데이터를 Data User에게 전달하기 위해서 TCP 플러그인을 사용하였다.
TCP 플러그인을 사용하는데 별다른 사전 설정이 필요하지 않지만 JDBC 플러그인을 사용하기 위해서는 연결 대상이되는 DB의 JDBC Driver가 필요하다.
전체적인 절차는 아래와 같다.
ojdbc.jar를logstash/logstash-core/lib/jar디렉토리에 복사한다.config/pipelines.yml파일을 편집하여pipeline id,pipeline 설정 파일(.conf) 경로등을 설정한다.
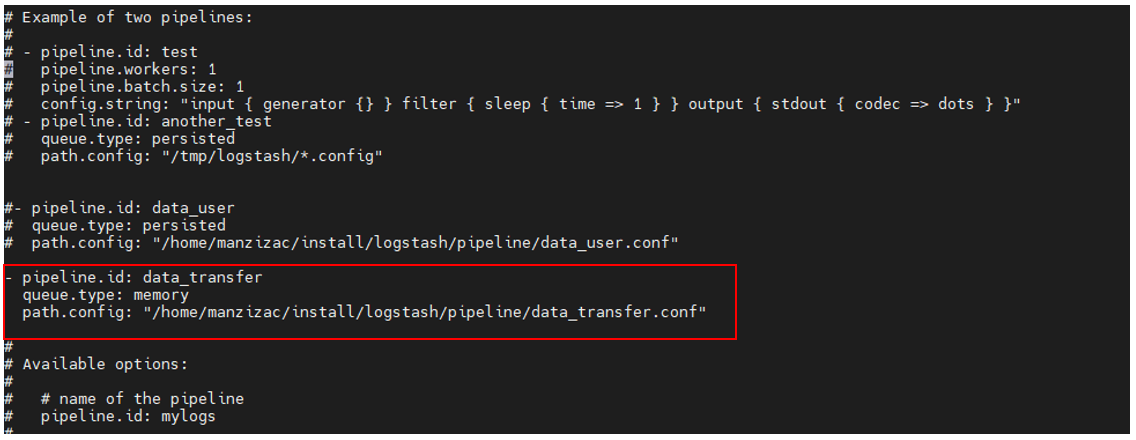
xxx.conf파일을 편집한다. 이 단계에서input에서 활용 될JDBC 플러그인을 설정하고output에서 활용 될TCP 플러그인을 설정할 수 있다.- 아래 그림은 위의 개요도와 같이
DB의SF_TX_DOM_TX_BS테이블로부터5초 간격으로 데이터를 읽어들이기 위해jdbc설정을 해주고tcp를 통해Data User에게 전달하기 위한 설정을 해준 모습이다.
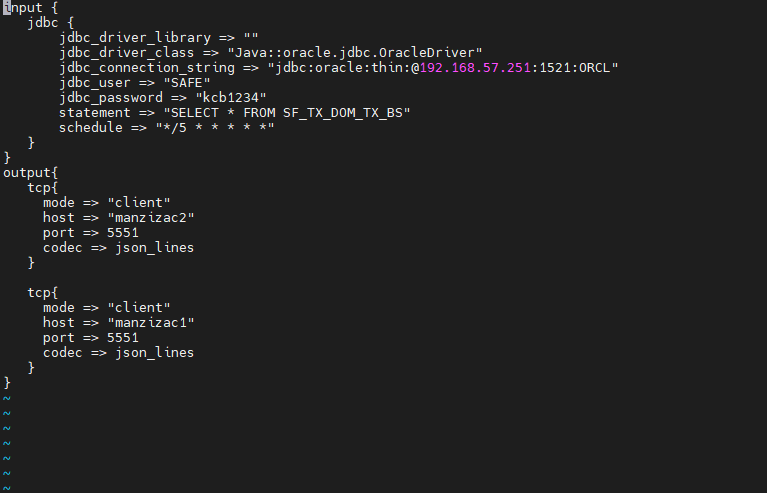
위처럼 절차대로 구성했다면 Data Transfer의 구성은 끝난셈이다. Data Transfer의 역할을 다시 살펴보면
JDBC 플러그인을 활용하여 오라클 DB로부터 데이터를 5초 간격으로 불러온다.- 읽어들인 데이터를
TCP 플러그인을 활용하여Data User(manzizac1, manzizac2)에게 전달한다.
(2) Data User 설정
TCP 플러그인을 활용한 데이터 입력 구성과 File 플러그인을 활용한 데이터 출력 구성
개요도에서 (2)번과 같이 Data Transfer과 TCP 통신을 하기 위해 Data User는 input 단계에서 TCP 플러그인을 사용해야 한다. 또한 (3)번과 같이 데이터를 로컬에 파일 형태로 저장하기 위해서 File 플러그인을 사용한다.
Data User는 패키지에 내장된 TCP 플러그인, File 플러그인을 사용하기 때문에 별다른 추가 구성 없이 pipelines.yml 파일과 xxx.conf 파일만 편집함으로써 구성을 완료할 수 있다.
config/pipelines.yml파일을 편집하여pipeline id,pipeline 설정 파일(xxx.conf) 경로등을 설정한다.xxx.conf파일을 편집하여input에서 활용 될TCP 플러그인을 설정하고output에서 활용 될File 플러그인을 설정한다.
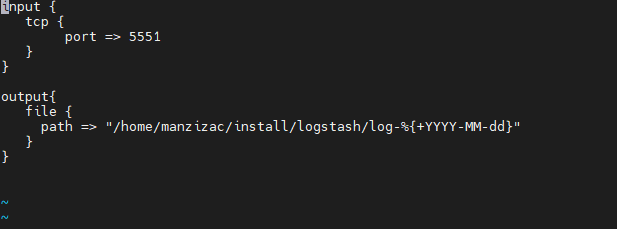
위처럼 절차대로 구성했다면 Data User의 구성은 끝났다. Data User의 역할을 다시 살펴보면
TCP 플러그인을 활용하여Data Transfer로부터 데이터를 전달받는다.- 전달받은 데이터를
File 플러그인을 활용하여 특정 경로에 저장한다.
(3) Data File 확인
이상없이 수행되었다면 Data User의 .conf파일에서 지정한 output 경로에 전달받은 데이터가 저장된 것을 확인할 수 있다.