Hashing
지난 알고리즘 이론 포스팅에서는 이진 탐색 트리에 대하여 설명하였다. 이번 포스팅에서 설명할 Hashing은 이진 탐색 트리와 같이 Dynamic Set(Serach Structure)를 구현하는 효과적인 방법 중 하나이다.
Dynamic Set에 대해서 다시 한 번 간단하게 설명하자면 Search, Insert, Delete 연산을 보다 효율적으로 수행하기 위한 자료구조라고 할 수 있겠다.
Hash table
해쉬 테이블은 Dynamic Set을 구현하는 효과적인 방법 중 하나이다. 적절한 가정 하에서 평균적인 탐색, 삽입 삭제 시간은 O(1)을 갖는다. 하지만 보통 최악의 경우에는 O(n) 시간복잡도를 갖는다.
사실 Hasing의 경우에는 시간복잡도를 예측하기 조금 애매한 부분이 있다. 그 이유는 천천히 살펴보도록 하자.
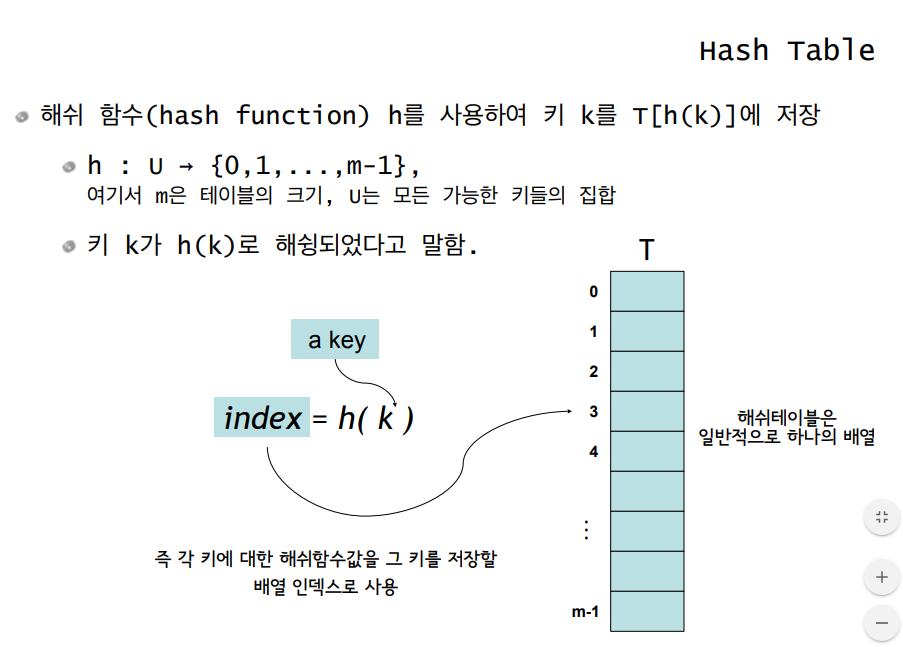
위 그림에서 볼 수 있듯 해쉬 테이블은 해쉬 함수 h의 반환값 h(key)를 인덱스로 하는 배열 T에 저장한다. 다시말하자면 어떤 key를 저장할 때 h(key)의 반환 값을 인덱스로 갖는 T[h(key)]에 저장한다.
조금 만 더 정리해보자.
해쉬 함수를 이용해서 key를 저장할 인덱스를 정한다. 그리고 이 인덱스를 배열에 저장하는데 이 배열이 바로 해쉬 테이블이 된다. 즉, 해쉬 테이블은 하나의 배열정도로 생각하면 된다.
해쉬 테이블은 M개의 저장 가능한 슬롯을 가지고 있다. 이 배열에 어떤 Key를 저장하고 싶다면 h(key)의 결과값을 인덱스로 활용하여 저장한다. 만일 key = "hello", h("hello") == 12라면 T[12] == "hello"가 되겠다.
위와 같이 h(key)의 반환값이 해쉬 테이블의 인덱스가 되기 위해서는 해쉬 함수의 결과값이 해쉬 테이블의 인덱스 범위여야 한다.
- ex) [U : 양의 정수 집합], [h(key) = key%m (0…m-1의 값)]
m = 100,key = 1024라면100 % 1024 = 24이므로T[24] = 1024와 같이 저장
해쉬 함수의 예
-
모든
Key들을 자연수라고 가정 (사실 어떤 데이터든지 자연수로 해석하는 것이 가능하다.) - 예 : 문자열
- ASCII 코드 :
C=67,L=76,R=82,S=83. - 문자열
CLRS는 \((67 * 128^3) + (76 * 128^2) + (82 * 128^1) + (83 * 128^0) = 141,764,947\)
- ASCII 코드 :
- 해쉬 함수의 간단한 예 :
h(key) = key % m, 즉key를 하나의 자연수로 해석한 뒤 테이블의 크기 m으로 나눈 나머지- 항상
0 ~ m-1사이의 정수가 됨 - 물론 이 해쉬 함수를 사용할수는 없다. (너무 간단, 충돌과 같은 문제가 발생할 소지가 너무 큼)
충돌(Collision)
충돌은 두 개 이상의 서로 다른 키가 동일한 위치로 해슁되는 경우를 말한다. 즉, h("hello") = 13, h("hi") = 13이라면 둘 다 T[13]에 저장되어야 하는데 이런 경우를 충돌이라고 말한다.
만일 key의 집합의 크기가 해쉬 테이블의 크기 m보다 크다면 당연히 충돌이 발생할 수 밖에 없다.
해슁에서 충돌은 피할 수 없는 문제 중 하나이다. 예를 들어 정수의 집합을 생각해 보았을 때 이 집합의 크기는 -2,147,483,648 ~ 2,147,483,647에 달한다. 이 크기 만큼의 배열을 생성하는 것은 현식적으로 불가능하다.
다시말하자면 단사함수 (U >> M)가 불가능하다 (집합의 크기가 테이블의 크기보다 훨씬 크기 때문)
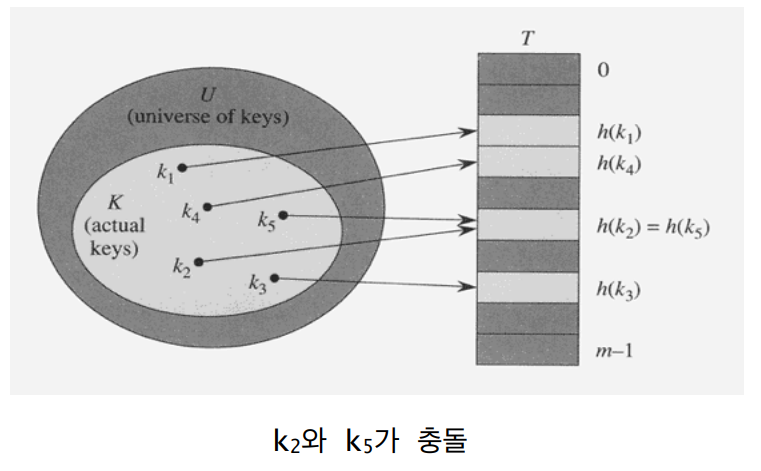
즉 우리는 해슁의 충돌을 배제할 수 없으므로 충돌이 발생했을 경우의 대처 방법에 대해서 고민해봐야 한다.
대표적인 충돌 해결 방법은 두 가지가 존재한다. 바로 Chaining과 Open Addressing이다.
Chaining에 의한 충돌 해결
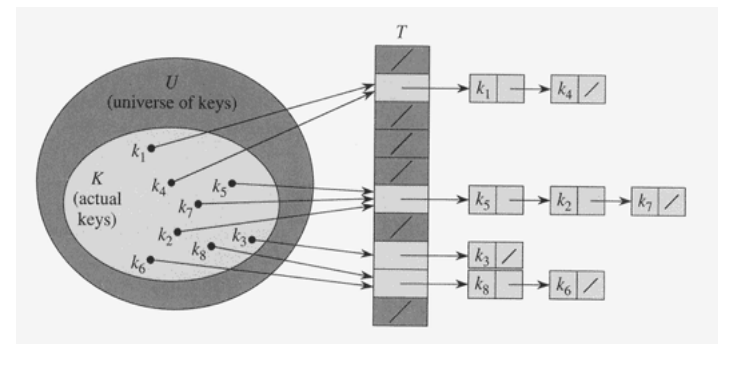
Chaning은 위 그림에서 볼 수 있듯 해쉬 테이블(배열)과 함께 연결 리스트를 사용하는 방법이다. 즉 동일한 장소로 해슁(충돌)된 모든 키들을 하나의 연결 리스트로 저장한다.
Chaning을 이용한 해슁을 택했을 때 아래와 같은 특징을 갖는다.
- 키의 삽입(Insertion)
key를 연결리스트T[h(key)]의 맨 앞에 삽입 :시간복잡도 O(1)- 중복된 키가 들어올 수 있고
중복 저장이 허용되지 않는다면삽입 시 리스트를 검색해야 한다. 따라서 중복 불허 시 시간복잡도는리스트의 길이에 비례
- 키의 검색(Search)
- 연결 리스트
T[h(key)]에서순차 탐색 - 시간 복잡도는 키가 저장된
리스트의 길이에 비례
- 연결 리스트
- 키의 삭제(Deletion)
- 연결 리스트
T[h(key)]로 부터 키를검색 후 삭제 - 일단 키를 검색해서 찾은 후에는
O(1)시간에 삭제 가능
- 연결 리스트
최악의 경우는모든 키가 하나의 슬롯으로 해슁되는 경우- 길이가
n인 하나의 연결리스트가 만들어진다. - 따라서 최악의 경우 탐색 시간은
O(n) + 해쉬함수 계산 시간
- 길이가
평균 시간복잡도는 키들이 여러 슬롯에 얼마나 잘 분배되느냐에 의해서 결정
포스팅 시작 때 시간 복잡도를 구하기가 애매하다는 언급을 했었다. 바로 위와 같이 키들이 얼마나 슬롯에 잘 분배 되었는지가 성능에 많은 영향을 끼치기 때문이다.
Open Addressing에 의한 충돌 해결
Chaining이 각 슬롯에 연결 리스트를 이용하여 충돌된 key들을 저장하는 방식이라면 Open Addressing은 해쉬 테이블 자체에 저장한다. 그럼 이전에 언급한 충돌은 어떻게 해결할까? Open Addressing에서 사용하는 충돌 해결 기법을 살펴보자.
-
Linear Probing(가장 기본적인 형태) -
Quadratic Probing -
Double Hasing
Linear Probing : Open Addressing의 충돌 해결 기법 1
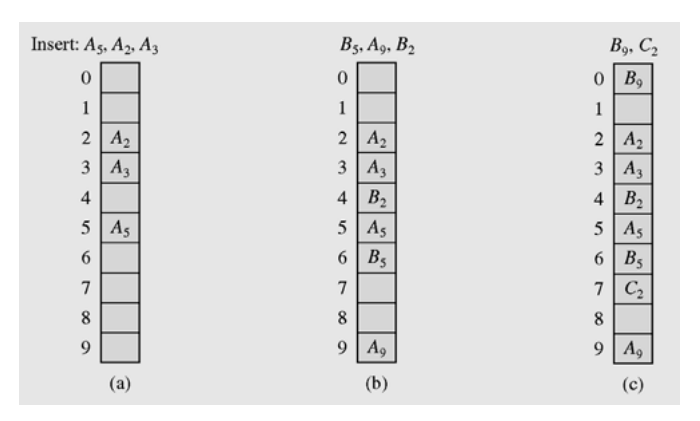
Linear Probing을 Open Addressing의 충돌 해결 기법은 다음과 같다.
h(key), h(key) + 1, h(key) + 2 … 순서로 검사하여 처음으로 빈 슬롯에 저장한다. 만일 테이블의 끝에 도달하면 다시 처음으로 circular하게 검사한다.
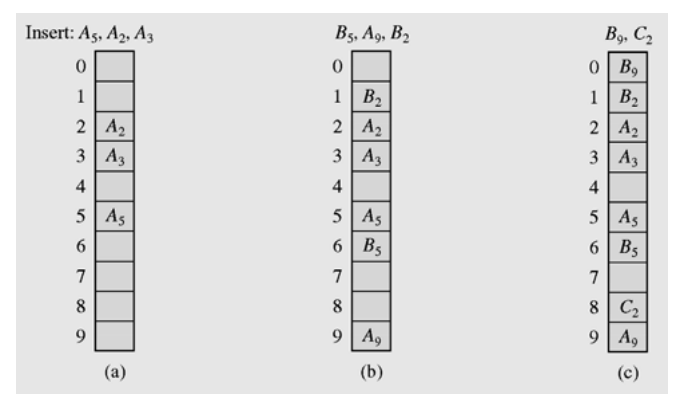
위 사진으로 예를 들면
-
처음에 들어온 값들을
해슁을 했을 때는 해당 슬롯이 비어있으므로 저장을 한다 (A5, A2, A3) -
그 다음 들어온 요소(
B2)가 삽입되어야 할 슬롯은 (2)인데 그 자리에는 이미A2가 저장되어 있다. -
그렇다면
h(B2) + 1 = 3이므로 다음 슬롯인3에 저장하려고 봤더니3번 슬롯에는A3가 저장되어 있다. -
다시 저장 가능한 슬롯을 찾기 위해
h(B2) + 2 = 4를 검사해 보았더니 비어있으므로4번 슬롯에B2가 저장된다. -
C2역시h(C2) = 2이므로2번 슬롯부터 저장할 위치를 차례로 찾아 결국h(C2) + 1,h(C2) + 2,h(C2) + 3… 순서로 진행했을 때 처음으로 나오는 빈 슬롯이7번 이므로 해당 슬롯에 저장한다.
이것이 바로 Open Addressing의 Linear Probing 충돌 해결 기법이다.
하지만 여기에는 단점이 존재한다. 바로 상당수 key들이 cluster를 구성한다는 점이다. 다시말하자면 테이블의 특정 부분에 뭉쳐져 있다.
이럴 경우 새로운 키가 insert 될 때 cluster 주변으로 삽입될 가능성이 상당히 높아지게되고 cluster는 점점 더 커지는 현상이 발생한다.
이러한 cluster의 증가는 search 연산에 영향을 미치게 되는데, 처음으로 빈 칸이 나올 때까지 검색을 하게 되므로 cluster의 길이가 길 수록 검색 시간이 길어질 수 있다. (연결 리스트 검색 시간과 거의 동일하게 될 수 있다.)
-
Primary Cluster: 키에 의해서 채워진 연속된 슬롯들을 의미 -
이런
cluster가 생성되면cluster는 더욱 더 커지는 경향이 생김
이와 같이 cluster 문제를 조금 완화시키기 위해 Quadratic Probing과 Double Hasing 방법이 등장한다.
Quadratic Probing : Open Addressing의 충돌 해결 기법 2
Linear Probing이 충돌 이후 슬롯을 검사하기 위해 h(key) + 1 , h(key) + 2.. 순서로 시도했다. 그리고 이는 cluster 문제를 발생시킨다고 설명했다.
Quadratic Probing의 경우에도 Linear Probing과 유사하지만 cluster를 완하시키기 위해 아래와 같은 빈 슬롯 검사를 한다.
\($h(key), h(key) + 1^2, h(key) + 2^2, h(key) + 3^2\)$
cluster의 완화를 위해 어떤 방법이 사용되었는지 주목하자.
Double Hashing : Open Addressing의 충돌 해결 기법 3
위에서 설명한 Linear Probing, Quadratic Probing과 달리 Double Hashing에서는 key마다 offset이 동일하다는 단점이 존재한다. 그리고 이렇게 offset이 동일할 경우 결국 cluster의 문제를 피할 수 없다.
반면 Double Hashing의 경우 offset이 동일하지 않은데, 그 이유는 이름에서 알 수 있듯 해쉬 함수를 두 개 사용하기 때문이다.
즉 서로 다른 해쉬 함수 h1과 h2를 이용하여 h(k, i) = (h1(key) + i * h2(key)) % m 으로 나온 값을 배열의 인덱스로 활용한다.
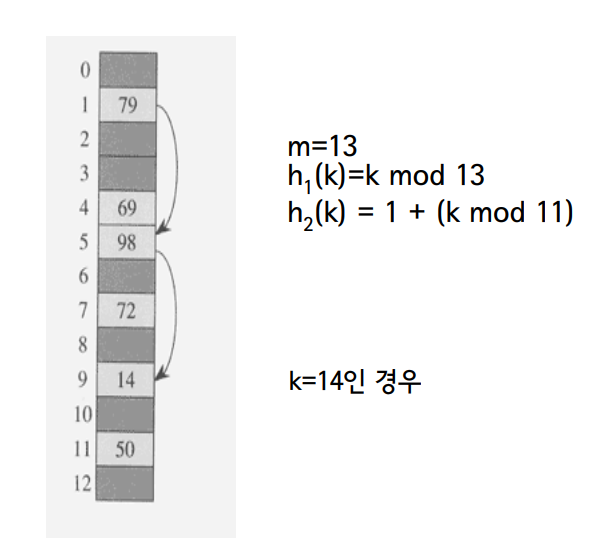
위 그림에서 살펴보면 key = 14인 경우와 key = 15인 경우 offset이 4, 5로 서로 다르다.
Open Addressing - 키의 삭제
Open Adderssing은 일반적인 방법으로 키를 삭제할 경우 태생적 한계 때문에 문제가 발생한다.
아래 그림을 살펴보자
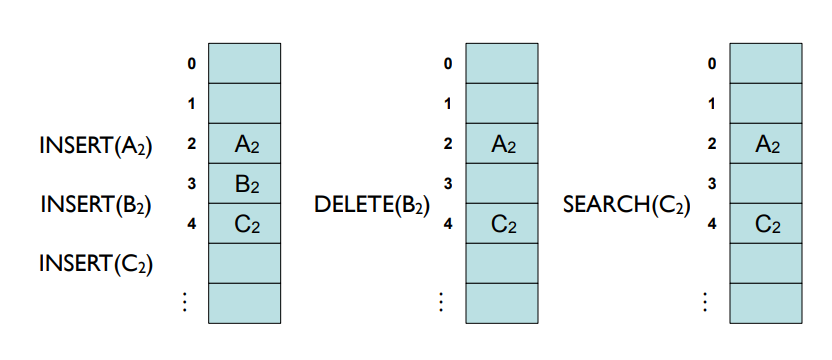
A2, B2, C2가 순서대로 모두 동일한 해쉬 함수값을 가져서 Linear Probing으로 충돌을 해결했을 때 위의 왼쪽 그림과 같은 상태를 갖는다.
여기서 가운데 그림과 같이 B2를 삭제 했다고 가정하자.
그리고 마지막 그림과 같이 C2를 검색한다고 가정했을 때 2번 슬롯에 A2가 저장되어 있으니 다음 슬롯인 3번 슬롯을 검사한다. 그런데 일전에 이미 B2를 지웠으므로 3번 슬롯은 비어있고, 이에 따라 C2가 저장되어있지 않다는 결과를 출력할 것이다.
Open Addressing에서는 위와 같은 문제를 해결하기 위한 방법이 필요하다. 즉, B2를 삭제한 이후에 C2를 기존의 B2 자리에 옮겨놓는 등의 처리가 필요하다.
좋은 해쉬 함수란?
지금까지 우리는 해슁에 대해서 살펴보고 해슁 충돌시 해결 방법들 (Chaning, Open Addressing)에 대하여 알아보았다. 하지만 아직 우리는 해쉬 함수에 대해서 알아보지 않았다. 해슁에 있어 중요하게 고려해야 하는 부분은 key를 저장할 위치를 적절히 계산해주는 해쉬 함수(h)이다.
이 해쉬 함수를 어떻게 구현하느냐에 따라 해슁의 성능이 결정된다고 보아도 과언이 아니다.
그렇다면 좋은 해쉬 함수란 무엇일까? 사실 해쉬 함수의 성능은 key들이 해쉬 테이블에 얼마나 골고루 분포되어 있는가에 따라 성능에 영향을 미친다. 결국 좋은 해쉬 함수라는 것은 비슷한 패턴을 가진 key더라도 상당히 다른 결과, 즉 “불규칙적인 결과값”을 가지는 것 을 말한다.
해슁의 목적에 따라 다르겠지만 일반적으로 좋은 해쉬 함수란 key들이 어떤 특정한(가시적인) 패턴을 가지더라도 “해쉬 함수 값이 불규칙적”이 되도록 하는것이 바람직하다. 즉, 해쉬 함수 값이 key의 특정 부분에 의해서만 결정되지 않아야 한다.
해쉬 함수
해쉬 함수를 구현하기 위한 몇 가지 기법들을 살펴보자.
- Division 기법 (가장 간단)
- h(key) = k % m
- 예 :
m = 20andkey = 91=>h(key) = 11 - 장점 : 한 번의 mod 연산으로 계산하기 때문에 빠르다.
- 단점 : 어떤
m값에 대해서 해쉬 함수의 key값이 특정 부분에 의해서 결정되는 경우가 있다.
- Multiplication 기법
- 0 ~ 1 사이의 상수
A를 선택 :0 < A < 1 k * A의소수 부분만을 택한다.소수 부분에m을 곱한 후소수점 아래를 버린다.
- 0 ~ 1 사이의 상수
- 예 :
m = 8,A = 13/32 (0.3xxxx),key = 21k * A = 21 * 13/32 = 273/32 = 8 + 17/32m*(k * A % 1) = 8 * 17/32 = 17/4 = 4.xxxx- 즉
h(21) = 4
위와 같은 Multiplication 방법을 택하면 두 개의 키가 유사한 패턴을 가지더라도 서로 상당히 다른 해쉬함수 값을 갖게된다. 즉 예측하기가 어렵다.
이는 해쉬 함수 값이 key의 특정 부분에 의해서만 결정되지 않아야 한다.는 조건을 충족시킨다.
Hashing in Java
-
Java의 Object 클래스는
hashCode()메서드를 갖는다. 따라서 모든 클래스는hashCode()메서드를 상속받는다. 이 메서드는 하나의 32비트 정수를 반환한다. -
만약
x.equals(y)이면x.hashCode() == y.hashCode()이다. 하지만 역은 성립하지 않는다. -
Object 클래스의
hahsCode()메서드는 객체의 메모리 주소를 반환하는 것으로 알려져 있다. -
필요에 따라 각 클래스 마다 이 메서드를
@Override하여 사용한다.- ex)
Integer클래스는 해당 객체의 정수 값을 그대로hashCode로 사용한다.
- ex)
해쉬 함수의 예 : hashCode() for String in Java
사용자 정의 클래스의 예
HashMap in Java
자바에서 사용하는 HashMap의 특징을 알아보기 전에 필요한 용어인 load factor와 HashMap에서 사용하는 해쉬 함수를 알아보자.
-
load factor: 보통의 경우해시 테이블의 크기(m)가실제 사용되는 key의 개수(n)보다 적은 해쉬테이블을 사용한다. 이 때n/m을load factor라고 한다. 즉, 해쉬 테이블의 한 슬롯에 평균 몇 개의 키가 매핑되는가를 나타내는 지표 로써 활용된다. -
HashMap에서 사용하는해쉬 함수
자바에서의 HashMap은 위와 같은 해쉬 함수를 사용한다. 그리고 내부적으로 하나의 배열을 해쉬 테이블로 사용한다.
또한 충돌 해결을 위해 chaning을 사용한다. 즉, 배열의 각 슬롯에 연결 리스트를 두어 충돌을 해결한다.
이 외에도 위에서 설명한 load factor(0 ~ 1 사이의 실수)를 지정할 수 있는데, 만약 (저장된 key의 개수/해쉬테이블 크기)가 load factor 초과 시 더 큰 배열을 할당 하고 저장된 키들을 재배치한다 (re-hashing)
참고 및 출처
인프런 권오흠 교수님 강좌