이진 검색 트리

일종의 다이나믹 셋 또는 Search Structure이다.
즉, 데이터들이 고정되어있지 않고 새로운 데이터가 추가되거나 기존의 데이터가 삭제되는 등 내용물이 가변적인 자료구조이다.
-
여러개의 키를 저장한다.
-
다음과 같은 연산들을 지원하는 자료구조
- Insert : 새로운 키의 삽입
- Search : 키 탐색
- Delete : 키의 삭제
만일 나이브하게 Search Structure를 구현한다고 하면 배열 또는 연결 리스트가 자주 사용되겠다. 이 경우 두 가지 경우가 존재하는데 정렬을 해서 저장하거나 정렬 없이 저장하거나 이다.
| - | - | search | insert | delete |
|---|---|---|---|---|
| 배열 | 정렬 | logN | O(n) | O(n) |
| 배열 | 정렬x | O(n) | O(1) | O(1) |
| 연결리스트 | 정렬 | O(n) | O(n) | O(1) |
| 연결리스트 | 정렬x | O(n) | O(1) | O(1) |
연결 리스트의 경우 정렬이 되어있더라도 구조적으로 binary search가 불가능하다.
이유는 연결 리스트에서는 2/n 번째 노드를 한번에 꺼낼 수 없기 때문이다.(배열처럼 인덱스가 존재하지 않음)
위 표를 보았을 때 나이브하게 배열이나 연결리스트로 구현했을 경우 4가지 방법 중 어떤 방법을 취하더라도 적어도 하나는 O(n) 시간복잡도를 피할 수 없다.
다양한 방법들이 존재
-
정렬 혹은 정렬되지 않은 배열이나 연결리스트를 사용(Insert, Search, Delete 중 적어도 하나는 O(n))
-
이진 탐색 트리(Binary Search Tree), 레드-블랙 트리, AVL-트리 등의
트리에 기반한 구조들 사용 -
Direct Address Table, 해쉬 테이블 등 사용
기본적으로 트리를 사용하는 방식, 해슁을 사용하는 방식이 Dynamic Set을 구현하는 일반적인 방법이다.
그리고 이번 장에서는 탐색 트리 중 가장 기본이라고 할 수 있는 이진 탐색 트리를 살펴본다.
검색 트리
-
Dynamic Set을트리의 형태로 구현 -
일반적으로
Search,Insert,Delete연산이 트리의 높이(height)에 비례하는 시간복잡도를 가짐 -
이진 탐색 트리, 레드-블랙 트리, B-트리 등
검색 트리는 원래의 데이터 자체가 트리의 구조를 갖는 것이 아니라 SELECT, INSERT, DELETE의 “연산 효율을 높이기 위해서” 트리 구조로 구현한 자료구조이다.
이진 검색 트리(Binary Search Tree)
-
이진 트리 이면서
-
각 노드에 하나의 키를 저장한다.
-
각 노드
v에 대해서 그 노드의 왼쪽 서브트리에 있는 키들은 key[v]보다 작거나 같고, 오른쪽 서브트리에 있는 값들은 크거나 같다.
BST의 SEARCH
BST Search 슈도 코드

위 슈도 코드는 x를 루트로 하는 서브트리에서 k가 어디에 있는지 찾는 알고리즘을 Recursion으로 표현한 코드이다.

위 슈도 코드는 동일한 탐색 알고리즘을 Loop로 표현한 코드이다.
BST의 최소값과 최대값
이진 검색 트리에 저장된 값 중 최소값이나 최대값을 찾는 알고리즘은 간단하다. 이진 검색 트리의 구조상 최소값은 트리의 가장 왼편에 존재하고 최대값은 트리의 가장 오른편에 존재한다.

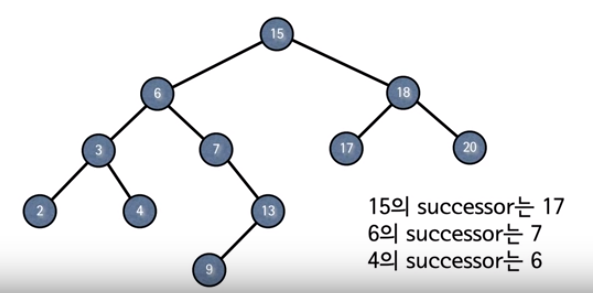
Successor
이번에 알아볼 Successor 탐색은 이진 탐색 트리의 Delete 알고리즘에서 활용된다.
-
노드
x의Successor란key[x]보다 크면서 가장 작은 키를 가진 노드이다. -
모든 키들이 서로 다르다고 가정한다.
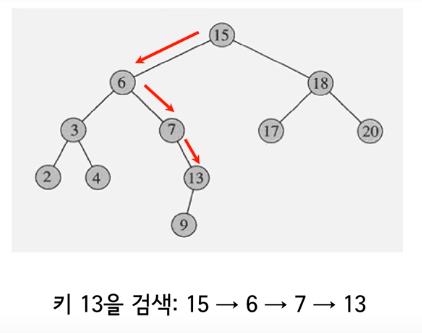
3가지의 경우가 있다.
-
노드 x의 오른쪽 서브트리가 존재한다면 오른쪽 서브트리의
최소값이Successor가 된다. - 오른쪽 서브트리가 없는 경우, 어떤 노드
y의 왼쪽 서브트리 최대값이x가 되는 경우 그 노드y가x의Successor가 된다.- 부모를 따라 루트까지 올라가면서 처음으로 왼쪽 자식을 갖는 노드
- 위에서 4, 13의 경우를 잘 생각해보면 알 수 있다.
- 위와 같은 노드
y가 존재하지 않을 경우Successor가 존재하지 않는다. (즉, x가 최대값임을 의미한다.)
Successor 탐색의 슈도코드

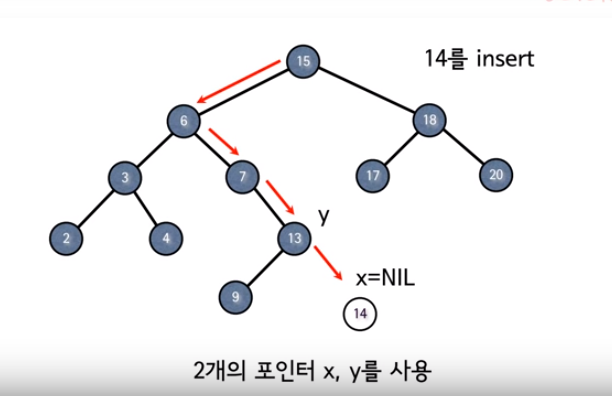
Insert 연산
-
새로운 노드를 이진 탐색 트리에 추가하는 것
-
이진 탐색 트리에서 INSERT 할 때는 기존 노드들의 자리를 바꾸지 않고 새로운 노드를 “leaf NODE”로 INSERT 한다
-
즉, 기존 노드의 자리나 구조를 바꾸지 않는다.
처음 삽입되는 노드가 ROOT가 되고 다음으로 삽입되는 노드들은 기존 트리의 노드들과 값을 비교하여 leaf node가 된다. 이점을 유의하자.
INSERT 슈도코드

- T: 이진 탐색 트리
- z : 새로 Insert 할 “노드” (데이터가 아님에 주의)
Delete 연산
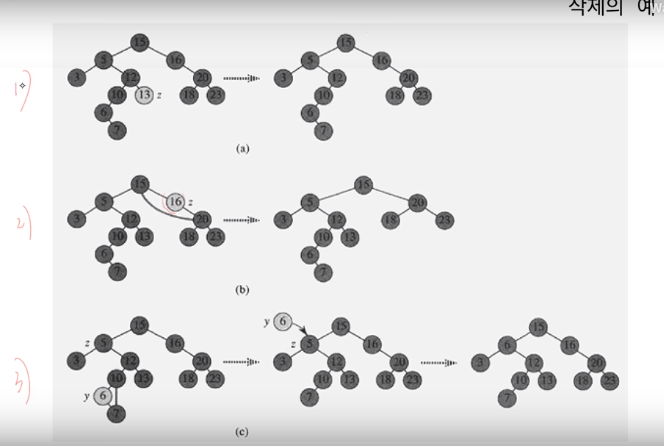
Delete의 경우 Search, Insert와 비교하여 조금 복잡한데, 3개의 케이스로 나누어서 진행한다.
-
case 1 : 자식 노드가 없는 경우
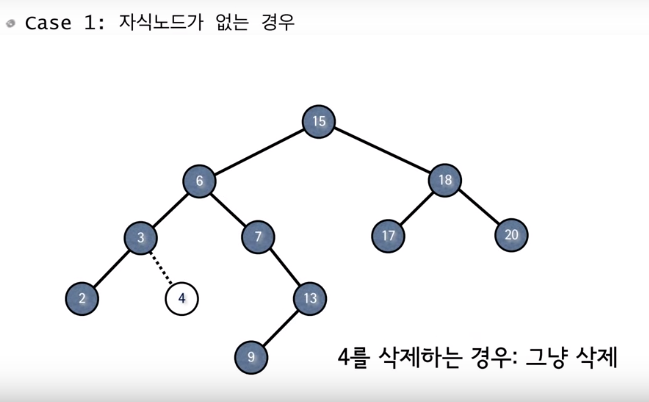
-
case 2 : 자식 노드가 한 개인 경우
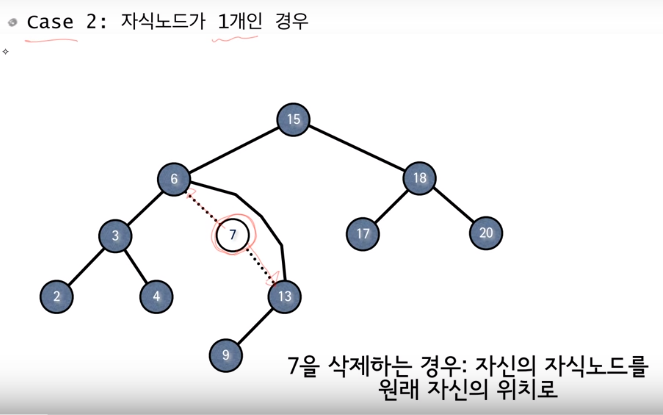
자식 노드가 한 개인 경우에 대하여 생각해 보자.
삭제하려는 노드(7)을 중심으로 보면 부모(6)도 유일하고 자식(13)도 유일하므로 연결 리스트와 같은 선형적인 구조이다.
즉, 연결리스트에서 가운데 노드를 하나 삭제하는 것과 단순하게 처리가 가능하다.
삭제하려는 노드가 부모의 오른쪽 자식이었다면 자식 노드를 오른쪽 부모의 자식으로, 부모의 왼쪽 자식이었다면 자식 노드를 부모의 왼쪽 자식으로 만들어주면 된다.
- case 3 : 자식 노드가 두 개인 경우
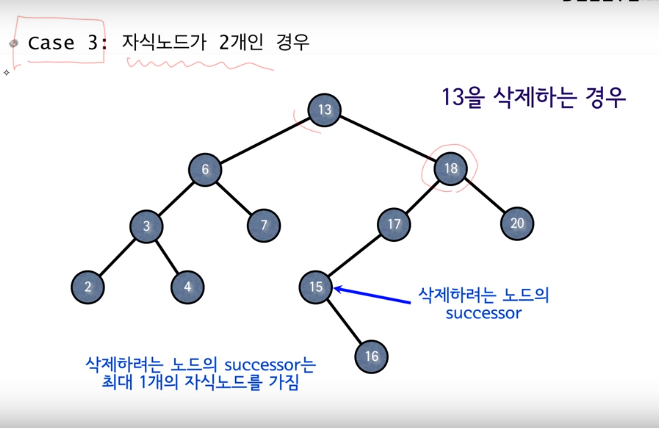
자식 노드가 두 개인 노드를 삭제하는 경우 생각보다 복잡해진다.
자식이 없거나 하나인 경우에는 그 노드를 삭제하더라도 쉽게 트리의 구조를 유지하거나 복원할 수 있었지만 자식 노드가 두 개인 경우 노드를 제거할 때 트리의 기본적인 구조가 흐트러지기 때문이다.
그래서 우리는 실제로 삭제하지 않고 복사하는 방법으로 진행한다.
만일 13을 삭제하려는 경우 13 노드는 그대로 두고 13이라는 데이터만 삭제 및 다른 노드에 저장된 데이터를 13의 자리로 옮겨온다.
그럼 도대체 누구를 옮겨와야 할까? 어떤 노드에 저장된 데이터를 옮겨올까?
여기서 바로 Successor 알고리즘이 활용된다.
이진 탐색 트리는 노드의 저장 구조에 규칙(왼쪽보다 크고 오른쪽보다 작음)이 있다.
따라서 삭제되는 노드와 가장 근접한 값인 Successor(또는 predecessor)를 활용하는 것이 좋다.
위 사진에서는 13의 Successor가 15이므로 기존 13의 왼쪽 서브트리와 오른쪽 서브트리의 관계를 만족한다. (15는 6보다 크고 18보다 작다.)
또한 Successor를 옮겨간다면 기존의 Successor는 왼쪽 자식을 가지지 않으므로 Successor의 자식 노드는 0개이거나 1개이다. 즉 Successor를 삭제(이동)하는 알고리즘은 비교적 간단하게 해결 가능하다.
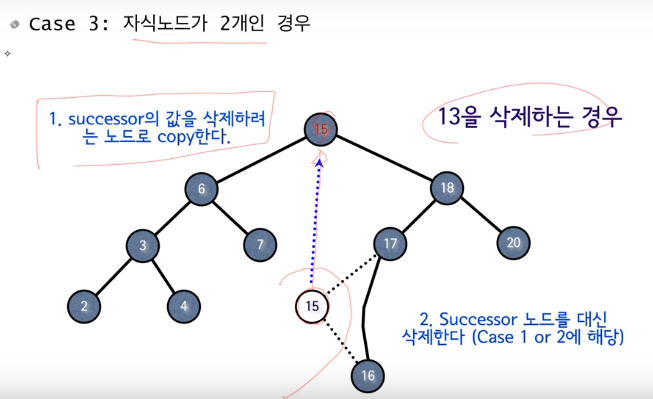
DELETE 예시
Delete 슈도 코드

- T: 삭제 트리
- z: 삭제할 노드
- y: 실제로 삭제할 노드 (자식이 0개이거나 1개 -> successor)
BST의 SEARCH, INSERT, DELETE 구현
참고 및 출처
인프런 권오흠 교수님 강좌